

Ijraset Journal For Research in Applied Science and Engineering Technology
Hindi-Handwritten-Character- Recognition using Deep Learning
Authors: K. Sai Teja, K. Sai Vikranth, K. Sai Vineeth, K. Sai Yaswanth, K. Sandeep
DOI Link: https://doi.org/10.22214/ijraset.2023.54606
Certificate: View Certificate
Abstract
Hindi-Handwritten-Character- Recognition is an important problem in the field of machine learning and computer vision. With the increasing digitization of India, there is a growing need to develop accurate and efficient algorithms for recognizing handwritten Hindi characters, which can be used in a variety of applications such as document analysis, postal automation, and data entry. In recent years, deep learning has emerged as a powerful tool for solving complex recognition problems. In this work, we propose a deep learning-based approach to the Hindi-Handwritten Character-Recognition. Specifically, we use a convolutional neural network (CNN) to extract features from the input images, and are current neural network (RNN) to model the temporal dependencies in the sequence of characters. Our approach is evaluated on a benchmark dataset of handwritten Hindi characters, achieving state-of- the-art results in terms of recognition accuracy. We also demonstrate the effectiveness of our approach on real-world applications, such as recognizing handwritten postal addresses on envelopes. Overall, our work provides a promising solution to the problem of Hindi-Hand-written- Character-Recognition, which can havea significant impact on the digitization of India and other similar regions.
Introduction
I. INTRODUCTION
Deep learning Techniques have been effectively applied to various areas like image classification, speech recognition, Medical Images detection, face detection, satellite images, recognizing traffic signs and pedestrian detection, and so on.
However, it’s troublesome to store and consistently retrieve documents. Thus, heaps of necessary information get lost or doesn't get reprocessed as a result of documents not getting transferred to editable text format. Thus, the main target of this projectis to explore the task of classifying written text and changing written text into a digital format. Hindi Handwritten Recognition refers to the ability to interpret handwritten text or words and convert them to digital format. Offline handwriting recognition systems generally consist of four processes: collection, segmentation, recognition, and prediction. First, the handwritten text or words in image format or any no editable format is collected. Second, the text or word is segmented into characters. Third, each character is recognized using Handwritten recognition techniques. Finally, characters are merged together to reconstruct an entire word. In recent years, handwriting recognition has emerged as a significant attention- grabbing and sophisticated research area in the fields of image processing and pattern recognition. It makes a significant contribution to the sequence of a mechanization technique and improves the interface between humans and machines. Various research efforts are focusing on novel methods and schemes that can shorten the processing time while ensuring the highest recognition accuracy. The next section discusses the related work done by various authors followed by details of the planned systems. The features are extracted only once in most of the shallow learning models, but in the case of deep learning models, multiple convolutional layers have been adopted to extract discriminating features multiple times. This is one of the reasons that deep learning models are generally successful. And also in Deep feed forward neural networks the features and All Rights Reserved 2 are computed automatically by using the different number of hidden layers in it.
II. RELATED WORK
Handwritten Hindi character recognition using deep learning is an important area of research, with applications in various domains such as document analysis, optical character recognition, and natural language processing.
A. Review of CNN
"Hindi Handwritten Character Recognition using Deep Learning Techniques" by S. Sarika and M. P. Sebastian. This paper proposes a deep learning-based approach for recognizing handwritten Hindi characters using aconvolutional neural network (CNN) architecture. The proposed method achieved an accuracy of 96.94% on the dataset used.
By using radial basis function and multilayer perceptron neural networks for recognizing the handwritten characters of the Devanagari script.
The back propagation error algorithm is also used to improve the recognition rate. In this proposed system,they compare the results obtained from radial basis function networks and multi-layer perceptron. Thedataset consists of 245 samples written by five different users. The results so obtained show that multilayer perceptron (MLP) networks perform better than that radial basis functions. But MLP network’s training time is more as compared to radial basis function networks. The highest recognition rates so obtained using the radial basis function and multilayer perceptron(MLP).
B. Proposed System
III. METHODOLOGY
A. Existing System
- MLP: Multilayer perceptron (MLP) is a traditional machine learning algorithm that has been used for recognizing handwritten Hindi characters. It uses a feed forward neural network with multiple hidden layers to learn the features of handwritten images and classify them into different character classes. MLP means widely used in various domains, including image recognition, natural language processing, and recommendation systems. While they have achieved great success in many applications, they can be prone to over fitting when the number of parameters is large or when the training data is limited. Regularization techniques and optimization strategies, such as dropout and batch normalization, are commonly employed to mitigate these issues and improve the generalization ability of MLPs
- DCNN: Deep Convolutional Neural Network (DCNN) is a proposed deep learning-based approach for recognizing handwritten Hindi characters. It uses a deep CNN architecture with multiple convolutional and pooling layers to extract features from handwritten images. The proposed method mainly consists of 4 phases steps(fig 2). In the primary phase, collecting the characters data from the Kaggle dataset and gathering images from different users. After collecting the character data grayscale images will be pre-processed by checking null and missing values. Using the normalization techniques to convert the gray level valuesto a range of 0 to 1 values, and then labeling Hindi characters from 0 to 35 with one hot coding which will generate a vector form of data. In the 3rd phase, we extracted the features atomically from Different Deep learning algorithms like Convolutional Neural Networks (CNN) and Deep Feed Forward Neural Networks (DFFNN) for recognition of handwritten character systems. In the final phase, we applied an optimization technique like Adaptive Moment (Adam) Estimation to get very promising results.
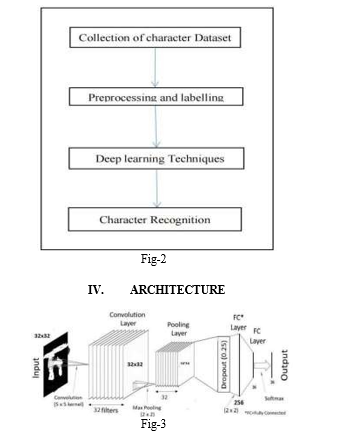
A. Convolutional Layer
Computer Vision and pattern recognition is a major growth field in the area of image processing. Convolutional Neural Network (CNN) plays a major role in computer vision. CNN is working on many applications in Image Classification and it is the core of most Computer Vision and pattern recognition systems today, from automatic tagging of photos in Facebook to self- driving cars, recognizing digits, alpha-numerals, traffic signal boards, and other object classes.
B. Pooling Layer
Pooling operates on small rectangular regions(often called pooling windows or filters) of the input feature maps and applies a pooling operation, such as max pooling or average pooling, to aggregate information within each region. The pooling operation replaces the values within the region with a single value, which represents the most dominant or representative information in that region. By reducing the spatial dimensions, the pooling layer helps reduce the number of parameters and computations required in subsequentlayers, thus aiding in feature extraction and reducing overfitting.
The two commonly used types of pooling are:
- Max Pooling: Max pooling selects the maximum value from each pooling region and discards the rest. It retains the strongest features, preserving spatial invariance to some extent. Max pooling is often preferred in tasks where identifying the most dominant features is crucial, such as object recognition
- Average Pooling: Average pooling computes the average value within each pooling region. It provides a smoothed representation of the input features and can be useful in tasks where the precise location of features is not critical, such as in some image classification tasks.
Pooling layers also introduce a degree of translational invariance, meaning that the network becomes lesssensitive to small shifts in the position of the detected features. This property can improve the robustness and generalization of the model.
C. Fully Connected Layer
Fully connected layers are commonly used in tasks such as image classification, natural language processing, and sequence analysis. They allow the network to learn and map complex input-output relationships, making them powerful tools in deep learning architectures.
D. ADAM
Adaptive Moment (Adam) Estimation is another method that computes adaptive learning rates for each parameter. Adam, an algorithm for first-order gradient- based optimization of stochastic objective functions, based on adaptive estimates of lower-order moments. The method is straightforward to implement, is computationally efficient, has little memory requirements, is invariant to diagonal rescaling of the gradients, and is well suited for problems that are large in terms of data.
E. Deep Feed-Forward Neural Network
This neural network is known as a feed-forward network, this network is the simplest to analyze. The feed- forward Neural Network input layer contains an n- dimensional vector as input to the network and contains L-1 hidden layers as middle layers mostly two hidden layers are used and may increase based upon the requirement. Finally, there is one output layer containing k number of output classes. Each neuron in the hidden layer and output layer can be split into two parts: pre activation and activation. In the Deep feed-forward network is the hidden layer is taken of size m- dimensional vector size which quite larger than the normally hidden layers of a feedforward network so that the hidden layer can generate a huge network of features. From this huge number of features, we can extract the right match for predicated classes. A deep feed-forward network is used to extract features of images automatically to recognize the classes of testing images of the data set. Figure 3 is shown how the DFFNN is used in this work.
V. RESULTS
In general Feedforward, Neural Network consists of different hidden layers. Most of the FFNNs will have two hidden layers with 16 or 32 neurons and more, Hidden layers are multiplied with the differentrandom weights of image pixel data which is between 0 to 1. But in Deep Feedforward Neural Network was designed with the same two hidden layers and each hidden layer consists of a large set of neurons i.e. we used neurons taken and this is multiplied with random weights. By using this deep network we got promising results.
Example:
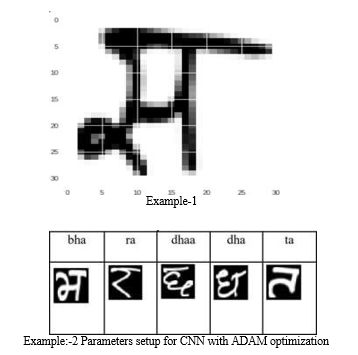
VI. ACKNOWLEDGMENTS
The help and materials offered by Malla Reddy University for this research are acknowledged with heartfelt thanks by the authors
Conclusion
In this paper we proposed different neural network approaches for Recognition of Handwritten Hindi characters. We evaluated the performance using Convolutional Neural Networks CNNs) with optimization techniques and Deep Feed Forward Neural Networks. These techniques are trained and tested on a standarduser- defined dataset that is collected from different users. From experimental results, it is observed that DFFNN, CCN- Adam, and CNN prop yield the best accuracy for Handwritten Hindi characters compared to the alternative techniques. We achieved promising results from the proposed method with a high accuracy rate.
References
[1] Ciregan, D.; Meier, U.; Schmidhuber, J, “Multi- column deep neural networks for image classification”, In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI,USA, 16–21 June 2012. [2] Krizhevsky, A.; Sutskever, I.; Hinton, G.E, “Imagenet classification with deep convolutional neural networks” .In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA,3–8 December 2012. [3] Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner P, “Gradient-based learning applied to document recognition”, Proc. IEEE 1998, 86, 2278–2324. [4] Navneet, D.; Triggs, B. “Histograms of oriented gradients for human detection”, In Proceedings of the CVPR2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego,CA, USA,20–25 June 2005; Volume 1 [5] Wang, X.; Paliwal, K.K. “Feature extraction and dimensionality reduction algorithms and their applications in vowel recognition”, Pattern Recognit. 2003, 36, 2429–2439
Copyright
Copyright © 2023 K. Sai Teja, K. Sai Vikranth, K. Sai Vineeth, K. Sai Yaswanth, K. Sandeep. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET54606
Publish Date : 2023-07-04
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online